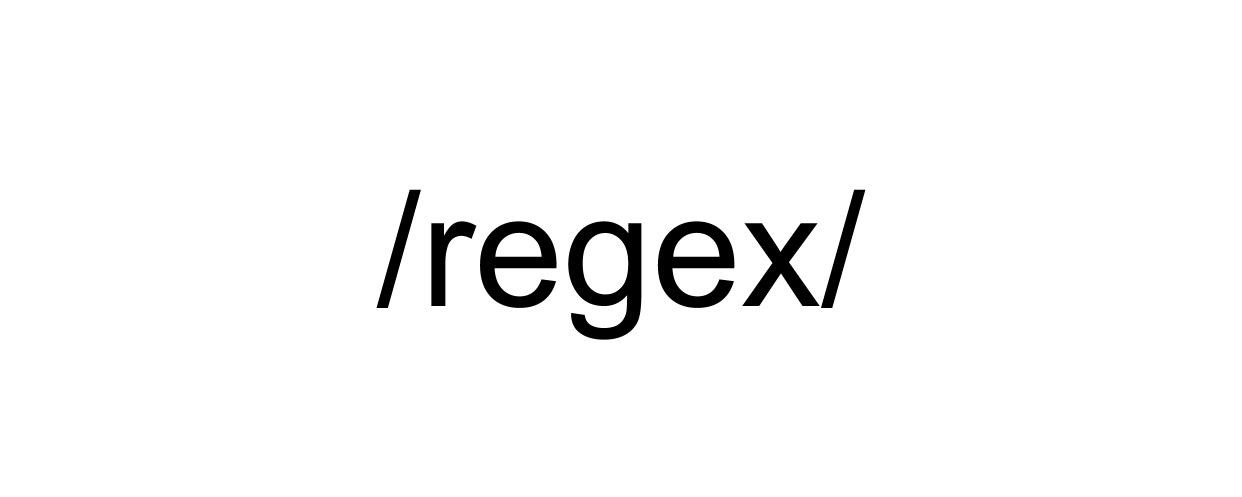本文最后更新于 2023-02-11 ,文中内容可能已过时,请谨慎使用。
展示博客主题的相关功能
1.播放 bilibili 视频
2.播放音乐
原网址: https://music.163.com/#/playlist?id=162024453
3.mapbox
4.插入图片
测试图片
图片2
5.插入链接
主页地址
6.添加横幅
7.插入 Youtube 视频
8.Latex 公式
下面是公式块:
$$
f(x)=\int_{-\infty}^{\infty} \hat{f}(\xi) e^{2 \pi i \xi x} d \xi
$$
这是一个行内公式:$ f(x)=\int_{-\infty}^{\infty} \hat{f}(\xi) e^{2 \pi i \xi x} d \xi $
9.pdf 文件内嵌
套用下面的模板,填入 pdf 的外链即可
< object data = "https://xxxx.pdf" type = "application/pdf" width = "100%" height = "700px" >
< embed src = "https://xxxx.pdf" >
< p > This browser does not support PDFs. Please download the PDF to view it:
< a href = "https://xxxx.pdf" > Download PDF</ a > .</ p >
</ embed >
</ object >
pdf 展示效果
This browser does not support PDFs. Please download the PDF to view it: Download PDF .
10.博客功能展示
在要置顶的文章的 Front matter 中添加weight: 1(按weight值从小到大排序)
11.新增视频 shortcodes
爱奇艺和搜狐不能直接用播放页面地址的视频id,使用页面的分享按钮获取完整iframe地址
爱奇艺是tvid部分,搜狐是bid部分。
{{< qqvideo r0029muuhfj >}}
{{< youku XMzk1NjM1MjAw >}}
{{< sohu 90742150 >}}
{{< acfun ac14349183 >}}
12.showcase shortcode
{{< showcase title="linux常用命令" summary="持续更新一些常用的命令" image="/images/all/ubuntu_20.png" link="/linux命令" *>}}
或
{{</* showcase "linux常用命令" "持续更新一些常用的命令" "/images/all/ubuntu_20.png" "/linux命令">}}
13.typeit
14.Hugo 文章内链优化显示
传入md文件名即可
调用方式(注意去掉\):
\{\{<blog_link "正则表达式入门">\}\}
\{\{<blog_link "conda相关">\}\}
2023-01-02
#regex #正则表达式
参考文档
1.正则表达式30分钟入门教程
2.https://r2coding.com/#/README?id=正则表达式
3.正则表达式必知必会
推荐书籍<!DOCTYPE HTML>
正则表达式必知必会(修订版)
豆
豆瓣评分
9.0
作者:福达 (Ben Forta) 出版:2015-1-1 / 人民邮电出版社 《正则表达式必知必会》从简单的文本匹配开始,循序渐进地介绍了很多复杂内容,其中包括回溯引用、条件性求值和前后查找,等等。每章都为读者准备了许多简明又实用的示例,有助于全面、系统、快速掌握正则表达式,并运用它们去解决实际问题。正则表达式是一种威力无比强大的武器,几乎在所有的程序设计语言里和计算机平台上都可以用它来完成各种复杂的文本处理工作。而且书中的内容在保持语言和平台中立的同时,还兼顾了各种平台之间的差异。通过阅读本书,读者能够在轻松的氛圉中迅速掌握正则表达式的精髓,并可立即运用所学,解决实际问题
什么是正则表达式 正则表达式是一些用于匹配和处理文本的字符串,主要的两个作用是搜索和替换
元字符表1.常用元字符
元字符 说明 ^a 字符串以a开头(定界符,匹配字符串开头) d$ 字符串以d结尾(定界符,匹配字符串结尾) \A 匹配字符串的开头 \Z 匹配字符串的结尾 \b 定界符,匹配前一个字符和后一个字符不全是\w的位置(单词的边界) . 匹配除换行符外任意字符 \d 匹配任意数字[0-9] \s 匹配任意的空白符,包括空格,制表符(Tab),换行符,中文全角空格等[\r\n\t\f\v ] \x 匹配16进制数字 \o 匹配8进制数字 \w 匹配数字,字母或下划线[0-9a-zA-Z_] (exp) 分组,匹配括号内的子表达式 | 逻辑或操作符 [] 匹配字符集合中的一个字符 - 定义一个区间如[a-z] \ 对下一个字符进行转义 ^\d{5,12}$:匹配5到12位的字符串
正则表达式中的word指的是出现至少连续1个的\w,word character指的是字母,数字及下划线
\b,^,$这些定界符只匹配一个位置,不匹配任何字符
注意
使用\A和\Z在多行模式下失效! 也就是说(?m)\A(...)\Z得不到(?m)^(...)$的匹配结果
限定符表2.常用限定符
限定符 说明 a* 字符a重复出现任意次 a? 字符a可以出现0或1次 a+ 字符a重复出现1次或更多次 a{3} 字符a正好出现3次 a{3,} 字符a重复出现3次或更多次 a{3,6} 字符a重复出现3到6次 字符转义如果先要查找元字符本身的话,需要进行转义.例如匹配字符.应该使用\.;匹配+,应该使用\+;匹配*,应该使用\*等等。如果要匹配字符\,应该使用\\.
正则表达式中需要转义的字符: * . ? + $ ^ [ ] ( ) { } | \
分支条件(Or)使用|连接多种匹配形式,匹配分枝条件时,将会从左到右地测试每个条件,如果满足了某个分支的话,就不会去再管其它的条件了。符合短路原则。
例如0\d{2}-\d{8}|0\d{3}-\d{7}:匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号(如010-12345678),一种是4位区号,7位本地号(0376-2233445)
字符类匹配某些特定字符集合可以使用[...],例如匹配任意数字字符可以使用[0-9],作用相当于元字符\d.
如果要匹配特定集合如小写元音字母可以使用[aeiou],[aeiou]的作用等价于a|e|i|o|u,匹配[]内任意一个字符。
正则表达式提供了一些字符类用以匹配特定的集合
表3.字符类
类 说明 [[:alnum:]] 任意字母和数字(同[a-zA-Z0-9]) [[:alpha:]] 任意字母(同[a-zA-Z]) [[:blank:]] 空格和制表(同[ \t]) [[:cntrl:]] ASCII控制字符(ASCII0到31和127) [[:digit:]] 任意数字(同[0-9]) [[:print:]] 任意可打印字符(ASCII32到126) [[:graph:]] 与[:print:]相同,但不包括空格(ASCII33到126)) [[:punct:]] 既不在[:alnum:]又不在[:cntrl:]中的任意字符 [[:space:]] 包括空格在内的任意空白字符(同[\f\n\r\t\v ]) [[:lower:]] 任意小写字母(同[a-z]) [[:upper:]] 任意大写字母(同[A-Z]) [[:xdigit:]] 任意十六进制数字(同[a-fA-F0-9]) 反义常用的反义代码
表4.反义代码
语法 说明 \W 匹配除数字,字母,下划线的其他字符[^0-9a-zA-Z_] \S 匹配任意非空格和回车字符[^\r\n\t\f\v ] \D 匹配任意非数字字符[^0-9] \B 匹配不是单词开头或结束的位置 [^x] 匹配除x之外的任意字符 [^aeiou] 匹配除aeiou之外的任意字符 举例:
\S+ 匹配不包含空白符的字符串 <a[^>]+>匹配用尖括号括起来的以a开头的字符串 后向引用(或回溯引用)使用小括号可以设置一个分组,(exp)指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。默认情况下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
子表达式允许嵌套,例如匹配一个ipv4地址的模式: (((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))\.){3}((25[0-5]|(2[0-4]\d)|1\d{2}|\d{1,2}))
后向引用用于重复搜索前面某个分组匹配的文本,最简单的应用比如重复,使用(aaa)\1{2}可以匹配aaaaaaaaa.
例如\b(\w+)\b\s+\1\b,\1代表分组1匹配的文本,\b(\w+)\b\s+\1\b的作用是可以用来匹配重复的单词,像go go, 或者kitty kitty。
这个表达式首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字(\b(\w+)\b),这个单词会被捕获到编号为1的分组中,然后是1个或几个空白符(\s+),最后是分组1中捕获的内容(也就是前面匹配的那个单词) (\1)
可以自定义组名,例如将上面的表达式的组1起名为word,使用\k<word>来调用
上面的表达式修改为\b(?<word>\w+)\b\s+\k<word>\b
表5.常用的分组代码
语法 说明 (exp) 匹配exp,并捕获文本到自动命名的组里 (?<name>exp)或(?'name'exp) 匹配exp,并捕获文本到命名为name的组里 (?:exp) 匹配exp,不捕获匹配的文本,拿不到分组的引用 零宽断言(或前后查找)表6.零宽断言类型
语法 说明 (?=exp) 正前向查找(positive lookahead),从exp往前查找,匹配的是exp之前的位置 (?!exp) 负前向查找(negative lookahead),匹配后面跟的不是exp的位置 (?<=exp) 正后向查找(positive lookbehind),从exp往前查找,匹配的是exp之后的位置 (?<!exp) 负后向查找(negative lookbehind),匹配前面不是exp的位置 断言用来声明一个应该为真的事实。正则表达式中只有当断言为真时才会继续进行匹配。
(?=exp)和(exp)的区别?
这两个模式所匹配的东西是一样的,都是子表达式exp,它们之间的区别只是被匹配到的exp有没有出现在最终的匹配结果里而已。使用零宽断言不会把exp包括在最终的搜索结果里。所以零宽断言匹配的结果长度为0,这也是为什么叫零宽的原因。
(?=exp)也叫零宽度正预测先行断言,它断言自身出现的位置后面能匹配表达式exp
(?<=exp)也叫零宽度正回顾后发断言,它断言自身出现的位置前面能匹配表达式exp
(?!exp)也叫零宽度负预测先行断言,它断言自身出现的位置后面不能匹配表达式exp
(?<!exp)也叫零宽度负回顾后发断言,它断言自身出现的位置前面不能匹配表达式exp
下面是一些样例:
\b\w+(?=ing\b)会匹配以ing结尾的单词的前半部分(除了ing以外的部分): 例如在查找I'm singing while you're dancing时会匹配sing danc (?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除了re以外的部分), 例如在查找reading a book时,它匹配ading (?<=\s)\d+(?=\s)|(\d(?=\s))匹配前后都是空格的数字串,这个表达式使用了前两种断言 \d{3}(?!\d)匹配三位数字且这三位数字后面不能是数字 (?<![a-z])\d{7}匹配前面不是小写字母的七位数字 注意
向前查找模式的长度是可变的,它们可以包含.和+之类的元字符,所以非常灵活。 而向后查找模式只能是固定长度,这是一条几乎所有的正则表达式实现都遵守的限制。 贪婪与懒惰当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符
例如a.*b会匹配以字符a开始字符b结束的最长字符串,假设文本为abababab那么将匹配整个字符串。这就是贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。
如果我们使用a.*?b那么就只会匹配最开始的ab这两个字符
注意如果文本为aabab,那么a.*?b匹配的结果将是aab,为什么不是最后的ab?
因为正则表达式有另一条规则,比懒惰/贪婪规则的优先级更高:最先开始的匹配拥有最高的优先权
表7.懒惰限定符
语法 说明 *? 重复任意次,但尽可能少重复 +? 重复1次或更多次,但尽可能少重复 ?? 重复0次或1次,但尽可能少重复 {n,m}? 重复n到m次,但尽可能少重复 {n,}? 重复n次以上,但尽可能少重复 正则表达式的替换使用(\w+[\w\.]*@[\w\.]+\.\w+)可以简单的查询文本中的电子邮件地址,比如文本(Hello, ben@forta.com is my email address.)中的ben@forta.com.
替换操作需要用到两个正则表达式:一个用来给出搜索模式,另一个用来给出匹配文本的替换模式。回溯引用可以跨模式使用,在第一个模式里被匹配的子表达式可以用在第二个模式里。
注意
在替换模式中回溯引用使用$1,$2,...而不是\1,\2,...
如果想把文本中的电子邮件地址全部转换成可以点击的链接,可以使用替换的正则表达式<a href="mailto:$1">$1</a>即可!
如果数据库中电话号码的保存格式为 313-555-1234,现在你需要把电话号码的格式重新调整为(313) 555-1234,可以设置搜索模式为(\d{3})(-)(\d{3})(-)(\d{4}),替换模式为($1) $3-$5
大小写替换表8.用于大小写的元字符
元字符 说明 \E 结束\L或\U转换 \l 将下一个字符转换为小写 \L 将\L到\E之间的字符全部转换为小写 \u 将下一个字符转换为大写 \U 将\U到\E之间的字符全部转换为大写 在正则表达式中嵌入条件处理 在正则表达式模式里可以嵌入条件,只有当条件得到(或者没有得到)满足时,相应的表达式才会被执行。这种条件可以是一个回溯引用(含义是检查该回溯引用是否存在),也可以是一个前后查找操作。
正则匹配中的条件使用?定义,比如
?匹配前一个字符或表达式,如果它存在的话 ?=和?<=匹配前面或后面的文本,如果它存在的话 表9.嵌入条件使用
语法 说明 (?(exp)yes|no) 如果exp匹配成功,使用yes表达式作为当前分组的子表达式;否则使用no表达式 (?(exp)yes) 同上,只是使用空表达式作为no (?(name)yes|no) 如果命名为name的组捕获到了内容,使用yes作为表达式;否则使用no (?(name)yes) 同上,只是使用空表达式作为no 利用回溯引用进行条件处理语法定义: ?(backreference)true-regex
其中?表示这是一个条件,括号内的backreference是一个回溯引用(或者说后向引用),true-regex是一个只在backreference存在时才会被执行的一个子表达式
例1: 你需要把一段文本里的<IMG>标签全都找出来,如果某个<IMG>标签是一个链接,需要将<A>和</A>标签匹配出来。
利用回溯引用+条件处理可以使用模式:(<[Aa]\s+[^>]+\s*>)?<[Ii][Mm][Gg]\s+[^>]+>(?(1)\s*<\/[Aa]>)来实现上面的要求
说明
(<[Aa]\s+[^>]+>\s*)?将匹配一个<A>或<a>标签(以及<A>或<a>标签的任意属性),这个标签可有可无(因为这个子表达式的最后有一个?)。接下来,<[Ii][Mm][Gg]\s+[^>]+>匹配一个<IMG>(大小写均可)及其任意属性。(?(1)\s*<\/[Aa]>是一个回溯引用条件,?(1)的含义是:如果第一个回溯引用(具体到本例,就是<A>标签)存在,则使用\s*<\/[Aa]>继续进行匹配(换句话说,只有当前面的<A>标签匹配成功,才继续进行后面的匹配)。
注意
?(1)检查第一个回溯引用是否存在。在条件里,回溯引用编号(本例中的1)不需要被转义。
因此,?(1)是正确的,?(1)不正确
刚才使用的模式只在给定条件得到满足时才执行一个表达式。条件还可以有否则表达式,否则表达式只在给定的回溯引用不存在(也就是条件没有得到满足)时才会被执行。
用来定义这种条件的语法是(?(backre-ference)true-regex|false-regex),这个语法接受一个条件和两个将分别在这个条件得到满足和没有得到满足时执行的子表达式。
例2: 匹配正确的北美电话号码格式,如(123)456-7890和123-456-7890
使用包含否则表达式的模式: ^(\()?\d{3}(?(1)\)|-)\d{3}-\d{4}$可以实现例2的要求
说明
(\()?匹配一个可选的左括号,但我们这次把它用括号括起来得到了一个子表达式。随后的\d{3}匹配3位数字的区号。(?(1)\)|-)是一个回溯引用条件,它将根据条件是否满足而去匹配)或-;如果(1)存在(也就是找到了一个左括号),则去匹配一个右括号);否则去匹配-。
利用前后查找进行条件处理前后查找条件只在一个向前查找或向后查找操作取得成功的情况下才允许一个表达式被使用。定义一个前后查找条件的语法与定义一个回溯引用条件的语法大同小异,只需把回溯引用(括号里的回溯引用编号)替换为一个完整的前后查找表达式就行了。
例3: 匹配美国的邮政编码(简称ZIP编码)。美国邮政编码有两种格式,一种是12345形式的ZIP格式,另一种是12345-6789形式的ZIP+4格式。只有ZIP+4格式才必须使用连字符来分隔前5位和后4位数字
匹配模式可以设置为\d{5}(?(?=-)-\d{4})
说明
\d{5}匹配前5位数字。接下来是一个(?(?=-)-\d{4})形式的向前查找条件。这个条件使用了?=-来匹配(但不消费)一个连字符,如果条件得到满足(那个连字符存在),-\d{4}将匹配那个连字符和随后的4位数
常用正则表达式文档
特别鸣谢
感谢CodeSheep大佬提供的文档,欢迎访问大佬的资源站
This browser does not support PDFs. Please download the PDF to view it: Download PDF.
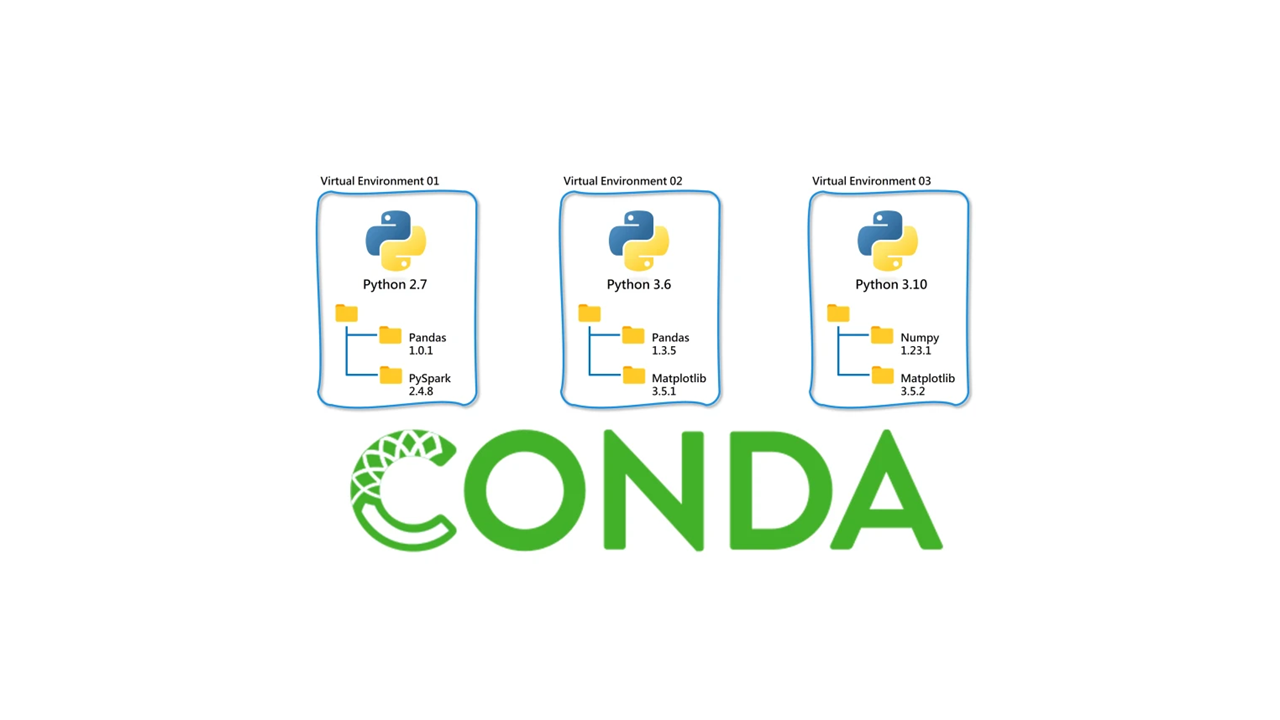
2023-02-01
#python #conda #linux
安装安装python3.8对应版本
wget -c https://repo.anaconda.com/miniconda/Miniconda3-py38_4.12.0-Linux-x86_64.sh 添加权限
chmod 777 Miniconda3-py38_4.12.0-Linux-x86_64.sh sh Miniconda3-py38_4.12.0-Linux-x86_64.sh 一直Enter,然后yes,最后确认一下安装路径
添加到环境变量,这里使用的是zsh
vim ~/.zshrc export PATH=/home/user/miniconda3/bin:$PATH 更换conda镜像源新建配置文件.condarc
vim ~/.condarc 更换为清华源, 在该文件中写入以下内容
channels: - https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/menpo/ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ ssl_verify: true 其他镜像源:
# 科大源 channels: - https://mirrors.ustc.edu.cn/anaconda/pkgs/main/ - https://mirrors.ustc.edu.cn/anaconda/pkgs/free/ - https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/ ssl_verify: true # 上海交大源 channels: - https://mirrors.sjtug.sjtu.edu.cn/anaconda/pkgs/main/ - https://mirrors.sjtug.sjtu.edu.cn/anaconda/pkgs/free/ - https://mirrors.sjtug.sjtu.edu.cn/anaconda/cloud/conda-forge/ ssl_verify: true 更换pip镜像源创建配置文件
mkdir ~/.pip cd ~/.pip vim pip.conf 配置如下:
[global] index-url = http://pypi.douban.com/simple [install] trusted-host=pypi.douban.com 常用命令conda --version # 查看conda版本 conda update -n base conda # 更新conda版本 conda info --envs 或者 conda env list # 查看安装的所有虚拟环境 conda create -n myenv python=3.8 -y # 创建myenv虚拟环境,python版本为3.8,-y表示跳过手动确认 conda remove --name myenv --all # 删除虚拟环境myenv conda activate myenv # 激活虚拟环境myenv, 不填环境名默认进入base conda list # 查看该环境下安装的所有包 conda install xxx # 安装包 conda uninstall xxx # 卸载包 conda deactivate # 退出当前虚拟环境 conda config --set auto_activate_base false # 关闭自动激活base环境 which python # 查看虚拟环境的python安装包位置 conda clean -p # 删除没有用的包 conda clean -t # 删除多余tar包 conda update --all # 更新所有包 requirements.txt导出与安装# pip批量导出包含环境中所有组件的requirements.txt文件 pip freeze > requirements.txt # pip批量安装requirements.txt文件中包含的组件依赖 pip install -r requirements.txt # conda批量导出包含环境中所有组件的requirements.txt文件 conda list -e > requirements.txt # conda批量安装requirements.txt文件中包含的组件依赖 conda install --yes --file requirements.txt 升级pip和condaconda install -y pip && pip install --upgrade pip # 升级base环境的conda conda update -y -n base -c defaults conda pip清理无用包pip freeze > allpackages.txt pip uninstall -r allpackages.txt -y
15.豆瓣图书卡片
\{\{< douban book="" uprating="9" title="客乡" url="https://book.douban.com/subject/35473516/" rating="8.9" author="[德]燕妮·埃彭贝克" pubdate="2023-1" publisher="北京日报出版社" summary="入选《卫报》21世纪百佳图书,莱比锡图书奖短名单作品——《客乡》以冰山一般的超然语调,讲述了柏林郊外一栋湖边别墅,几十年间不断变迁的居住在此的人们的故事。20世纪德国动荡的历史进程,在一个个激情、伤痛、遗憾与和解的故事中自陈其身。" img_url="https://img1.doubanio.com/view/subject/s/public/s34387147.jpg" >\}\}
作者:[德]燕妮·埃彭贝克 出版:2023-1 / 北京日报出版社
入选《卫报》21世纪百佳图书,莱比锡图书奖短名单作品——《客乡》以冰山一般的超然语调,讲述了柏林郊外一栋湖边别墅,几十年间不断变迁的居住在此的人们的故事。20世纪德国动荡的历史进程,在一个个激情、伤痛、遗憾与和解的故事中自陈其身。
16.豆瓣电影卡片
\{\{< douban movie="" uprating="6" url="https://movie.douban.com/subject/26995475/" name="风再起时" rating="6.4" director="翁子光" genre="剧情 / 动作 / 犯罪" year="2022" intro="张扬敢拼的磊乐(郭富城 饰)与内敛善谋的南江(梁朝伟 饰),在因缘际会下携手,破除旧规,立威造势,在磊乐太太蔡真(杜鹃 饰)的斡旋下,成为黑白两道人人皆知的“双雄探长”,二人自此叱咤香港三十年。然而在表面的平静与制衡之下,火并、谋杀、背叛、夺权……!" img_url="https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2887517387.jpg" >\}\}
导演:翁子光 类型:剧情 / 动作 / 犯罪
首播: 2022
张扬敢拼的磊乐(郭富城 饰)与内敛善谋的南江(梁朝伟 饰),在因缘际会下携手,破除旧规,立威造势,在磊乐太太蔡真(杜鹃 饰)的斡旋下,成为黑白两道人人皆知的“双雄探长”,二人自此叱咤香港三十年。然而在表面的平静与制衡之下,火并、谋杀、背叛、夺权……!
16.tab标签页